On the 12th of July 2022, the world of artificial intelligence and data science (specifically NLP) got exciting news in the Large Language Models(LLMs) field. The BigScience, an open collaboration of Hugging Face, GENCI and IDRIS and one of the most extensive research workshops in the field of NLP, has introduced complete transparency and open sourced multilingual large language model BLOOM clipped form of BigScience Large Open-science Open-access Multilingual Language Model. Let’s talk a bit more in detail using the following pointers.
Table of content
What is BLOOM?
Who can use BLOOM?
Technical specifications
What is BLOOM?
Bloom is one of those autoregressive large language models capable of generating text from a prompt on a massive amount of text data. This model is not limited to one language; it can produce such text in 46 languages and 13 programming languages. Furthermore, this model can also be extended to perform such NLP or text tasks it has been explicitly trained for, just by casting the process as a text generation task.
It is the first complete transparent multilingual LLM that took 176 billion parameters and the Jean Zay supercomputer for training. Building this model required the engagement of 1000 researchers from 70+ countries and more than 250 institutions for 117 days of training.
Who can use BLOOM?
Any one individual or organisation wanting to try and investigate this model can download, run and study from here. Before utilising it, we require to agree to these terms and conditions.
Since it is embedded in the Hugging Face platform, its implementations are the same as the other transformers of Hugging Face. This means it can be imported with transformers and run with accelerates.
This model can be utilised in some real-world use cases that require text generation like writing recipes, information extraction from articles, or composing new sentences utilising the series of texts. Also, it is an excellent example for many aspirant data science developers and researchers from where they can start their journey of learning software like PyTorch, apex, DeepSpeed etc., in a deeper direction.
Technical specification
BLOOM is a modified version of Megatron-LM GPT2 that includes only decoder architecture. Talking about the parameters and layer space, it contains 176 billion parameters, 70 layers and 112 attention heads with 14336-dimensional hidden layers. The objective function enabled by the model is cross entropy with mean reduction.
As discussed above, this model got trained on Jean Zay Public Supercomputer, which was provided by the French government. Some of the specifications of this computer are as follows:
384 A100 80GB GPUs (48 nodes)
CPU: AMD
CPU memory: 512GB per node
GPU memory: 640GB per node
Inter-node connect: Omni-Path Architecture (OPA)
Training of this model took 1.6TB of text(pre-processed), and the below pie chart represents the text distribution according to language in training data.
The model’s training started on the 11th of march, and it is estimated that the end date of the training is 5th July 2022. The number of Epochs utilised in training is one, and the estimated cost of the training is Equivalent to $2–5M in cloud computing.
There are the following versions of BLOOM is available:
bloom-350m
bloom-760m
bloom-1b3
bloom-2b5
bloom-6b3
bloom (175B parameters)
Final words
We have seen what it takes to build this model and how it can help the Data Science community. By looking at the various things, we can say that it has the potential to become revolutionary in the field of NLP as the development team is considering it as just a beginning and not just a one-and-done model. You can try the BLOOM model here.
About DSW
Data Science Wizards (DSW) is an Artificial Intelligence and Data Science start-up that primarily offers platforms, solutions, and services for making use of data as a strategy through AI and data analytics solutions and consulting services to help enterprises in data-driven decisions.
DSW’s flagship platform UnifyAI is an end-to-end AI-enabled platform for enterprise customers to build, deploy, manage, and publish their AI models. UnifyAI helps you to build your business use case by leveraging AI capabilities and improving analytics outcomes.
In recent years, we can witness that artificial intelligence is becoming a need in every domain of the industry, and AI’s different domains, such as computer vision, natural language processing, and predictive modelling, are helping humans solve their use cases and problems more effectively and without the intervention of the humans. We can also enjoy the intervention of AI in our daily life, and humans are becoming more curious about this intervention. Banking sectors are also positively affected by the intervention of AI. In this article, we will cover some of the critical use cases of AI in the banking sector that is helping humans advance the banking sector.
Customer Engagement
This sector implies AI-enabled models to assist the customer during onboarding. These models are trained to perform step-by-step processes of customer onboarding. Natural conversation utilises digital channels. Bots are there to automate the services like processing the documents of customers and taking images from computer vision programs.
Some other vast implementations of OCR systems can be found to process the documents of the customer, and a variety of systems are there that help in performing document verifications of customers to make the customer onboarding faster and smooth. Since no human intervention is required, fewer human skills are necessary. It also helps the service provider to prevent their human workforce from performing repetitive and sometimes mundane tasks inside the premises.
WeChat messenger is an excellent example of engaging customers by utilising conversations. For instance, China Merchant Bank is one of the largest credit card companies using WeChat messenger to handle 1.5 to 2 million customers.
Customer Service
In a banking system, customer care, service and engagement programs play a crucial role in democratising the bank’s services among the customers and also help in enhancing sales and marketing of banking services. Nowadays, it is found that chatbots have replaced humans in customer care, and this also impacted the banking sector. While applying chatbots in such systems delivers a very high ROI in cost savings.
Embedding chatbots in the banking sector can be considered the most common application of AI in the banking sector. There are various tasks such as balance inquiry, statement production, and fund transfer that can be managed using these chatbots and applying such chatbots helps in reducing the overload of the channels like contact centres and internet banking channels.
HDFC bank’s chatbot named EVA is an excellent example of this use case where we can consider it as the banking assistance for the customers of HDFC and helping them with things like Branch addresses, IFSC codes, loan and interest rate information.
Automatic Advice Systems
In traditional banking and finance systems, we find that banks employ humans to advise the customers and clients regarding investments, loaning, credit cards and debit card schemes. However, as the number of customers and their requirements increases, it becomes challenging for humans to manage such big data and provide beneficial advice to everyone.
Artificial intelligence and data science intervention in banking and finance systems have made this task very easy. AI-enabled models are being developed and prepared to perform automatic advice procedures with a touch of personalisation for everyone. These models are learned to give the best advice to customers according to the requirements, and that makes them a personalised advice system in banking. Also, they are beneficial in reducing the time of the banking procedures.
For example, ICICI banks in India blended an RPA( robotic process automation) with their systems and successfully cut loan processing time in half.
Predictive Analysis and Modelling
One of the most common use cases of artificial intelligence is to perform predictive analysis and modelling using the data. These modelling procedures find the correlation between the data points and variables and tell about the future possibilities. Traditionally it was complicated to understand and predict such possibilities, and the intervention of AI models made it very easy. Using such models, we can have information about sales opportunities, cross-sell opportunities, share market statistics and social media channels. These pieces of information can lead to a direct revenue impact. We can also calculate metrics around operational data in the banking system so that predicting values can become an easy task. There are various examples of static models and neural networks being consumed frequently to predict near or far future trends and patterns.
Security
AI can be utilised for security purposes, which not only helps in the banking system but also allows being applied in different domains. For example, we know that models work by understanding patterns hidden in the data, so if data about the previous threats are given to these models, they can help us find current and future threats. Furthermore, these predictions can help baking systems to prevent attacks and fraudulent activities.
There is various software such as SEON, SAS, ThreatMetrix and Feedzai that is helping in preventing banks from threats and fraud. For example, Citi bank employs Feedzai for three significant protections: securing account openings, controlling transaction fraud, and stopping money laundering.
Security on the premises of banks is also the main topic to be covered when it comes to security. These security purposes include enabling security cameras and security guards throughout the premises. Artificial intelligence also helps these systems to enhance the level of security by utilising face recognition and biometric systems. However, these systems can also be integrated with bank applications to enhance the security on the customer side.
Credit Scoring
One of the major impacts of AI on the banking system can be found in credit scoring, where the model trained using the history and demographics of users can help determine the creditworthiness of clients and customers. Such an application becomes very helpful for the banking systems where they can predict the credit scores in a very robust and accurate way.
Since demographics are applied in training, these models sometimes don’t require a vast history of the users and can work by comparing the demographics of the other users to tell the credit score of a new user.
Softwares such as GiniMachine, LenddoEFL, ZestFinance, Kreditech and SAS Credit Scoring are leading AI-enabled software for credit scoring.
Decision Making
Various decisions can be taken using historical data, which can have a high impact on the banking systems. Such models work in a system where expert data is stored in a database and utilised to make strategic decisions like deciding workflow between different departments, cash flow management, and document flow strategy within the bank.
Various banks are utilising analytical AI-based tools such as AlphaSense, which is an AI-enabled search engine that uses the processes of Natural Language Processing and also helps with task routing.
Conclusion
In the banking sector, the intervention of artificial intelligence has put a lot of scope in various tasks in the knowledge workforce and in preventing banks from cyber risks and fraudulent activities. Enabling AI in banking sectors has enhanced the competition between different banks. AI models are improving banking services from being applied to customer services to making impactful strategic decisions.
About DSW
Data Science Wizards (DSW) is an Artificial Intelligence and Data Science start-up that primarily offers platforms, solutions, and services for making use of data as a strategy through AI and data analytics solutions and consulting services to help enterprises in data-driven decisions.
DSW’s flagship platform UnifyAI is an end-to-end AI-enabled platform for enterprise customers to build, deploy, manage, and publish their AI models. UnifyAI helps you to build your business use case by leveraging AI capabilities and improving analytics outcomes.
In the field of data science, we mainly find a variety of algorithms or models to perform regression and classification modelling. Logistic regression can be considered the first point of your learning line of data science, classification and predictive modelling. Since it comes under the regression model family it uses a curve to classify data in classes. We at DSW highly prefer to model small use-cases and problems utilising such small algorithms because these are highly robust and easy to interpret. In this article, we are going to talk about logistic regression. Let’s just start by what the logistic regression algorithm is.
What is logistic regression?
Logistic regression is one of the most basic and traditional algorithms or models that comes under the supervised machine learning classes used for classification and predictive modelling. In basics, these algorithms can be used to model the probability of an event or a class. Since it comes from the regression class models it uses the lines or curves to model the data and we use it where the dataset we have can be separated using lines, and the outcome from the model is required to be binary or dichotomous.
That means we use logistic regression for binary classification and binary classification works when the target variable is separated into two classes. Simple examples of binary classification are yes/no, 0/1, win/loss etc.
There are two types of logistic regression
Simple logistic regression
Multiple logistic regression
Where simple logistic regression is utilised where only one independent variable is affecting the dependent variable and multiple logistic regression is utilised when there are more than two independent variables affecting the dependent or target variable.
However, this can also be extended to the multinomial logistic regression and ordinal logistic regression where the number of classes is discrete in more than two classes or more than two classes of an ordinal nature. Since we majorly believe that using one line we can not separate more than two classes accurately we are going to learn about the simplest versions of logistic regression that can be utilised for binary classification. Let’s see how this algorithm works.
How does Logistic Regression Work?
As discussed above logistic regression works by separating linear separable data just like linear regression. To understand the working of logistic regression we are required to understand the mathematics behind it.
Mathematics
Let’s consider there is one predictor or independent variable ‘X’ and one dependent variable y and the probability of y being 1 is P. In such a situation the equation of linear regression can be written as:
p = mx + m0 …..(1).
The right side of the above equation is a linear equation and can hold beyond the range 0 to 1. And we all know that probability can vary between 0 to 1 only. So to overcome that we can predict odds in place of probability using the following formula:
Odds = p/(1-p)
Where,
p = probability of occurrence of any event.
1-p = probability of non-occurrence of any event.
According to odds, 1 can be written as:
p/(1-p) = mx + m0 .….(2)
Here we also need only a positive number that can be handled using the log form of the left side of equation 2.
log(p/(1-p)) = mx + m0 …..(3)
To recover the above equation we need to use the exponential form of both side
e(log(p/(1-p)) = e(mx + mo) …..(4)
While simplifying equation four we will get the following equation
p = (1-p)(e(mx + mo)) ..…(5)
We can also write this equation as follows
p = p((e(mx + mo))/p — e(mx + mo))
p =e(mx + mo)/(1 + e(mx + mo)) .….(6)
Now we can also multiply e(mx + mo) / e(mx + mo) on equation 6.
p = 1/(1 + e-(mx + mo))
Above is the final probability that logistic regression uses if the above-given condition is true. But if there are n predictors then the calculatory equation will be as follows
p = 1/(1+ e-(m0+m1x1+m2x2+m3x3+ — — +mnxn))
The above is the final equation of logistic regression when there is n predictors. Some experienced persons compare this equation with the sigmoid function because it also controls the range of output between 0 to 1.
In the above, we can see how we started with the linear equation and ended with the curve.
A Mathematically sigmoid function can be written as follows:
(z) = 1/(1+e-z)
In the above, we are required to replace z with e-(mx + mo) to make it an equation of logistic regression. Looking at the equation we can say the below image will be a representation of the working of logistic regression.
In the above image, we can see how logistic regression keeps the curve between the values 0 and 1. Now before utilising logistic regression on any data we are required to consider some of the assumptions. Let’s take a look at the assumptions.
Assumptions
Before modelling data using a basic logistic regression algorithm we are required to consider the following assumptions:
If any extensions are not applied then data needs to have a dependent variable with binary data points.
The data points under the data need to be independent of each other.
The independent variables of the data need to have no or small multicollinearity with each other.
The independent variables and their odds need to be linear to each other.
One thing that sometimes becomes mandatory according to the suggestions is that it is good to work with a large data size while utilising logistic regression in the process.
Here we have seen some of the assumptions that need to be covered before applying logistic regression. Let’s see how we can apply logistic regression to any data.
Implementation
In this section, we will look at how we can apply logistic regression to data using the Python programming language. However, we can also use R, MATLAB and excel for performing logistic regression but considering the size of the article we are using only Python.
In Python, Sklearn is a library which provides functions for applying every kind of machine learning algorithm in our datasets and for applying logistic regression we have the LogisticRegression method under the linear_model package which we utilise here.
Let’s start with making a synthetic dataset using the make_classification function of Sklearn.
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=5, random_state=42)
Here we have created a dataset which has 1000 rows and 5 columns in the independent variable dataset and 1 dependent variable with two classes 0 and 1. We can validate it by converting these arrays in the pandas DataFrame.
import pandas as pd
df = pd.DataFrame(data=X)
df[‘Target’] = y
df
Output:
Here we can see all the independent and dependent variables in one place.
Before going for modelling we are required to know which variables from our dataset have a better correlation with the target variable. Let’s check the correlation.
import seaborn as sns
corr=df.corr()
sns.heatmap(corr, annot=True,
fmt=’.1%’)
Output:
Here we can see that variables 0, 1, and 3 have higher correlations with the target variable and we can consider them in the data modelling with logistic regression.
Let’s trim and split the datasets
X = X[:, [0,1,3]]
from sklearn.model_selection import train_test_split
Let’s import the function from Sklearn and model the data.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
Let’s make some predictions so that we can validate the model
y_pred = model.predict(X_test)
y_pred
Output:
Here we can see the prediction made by the model. Now we need to evaluate this model.
Evaluation
Evaluation of a classification model can be done in various ways. Since it’s a binary classification model we find that there are two prime methods which can help us in the evaluation. These methods are as follows:
Accuracy score
It is the universal method for evaluation of any classification model which mainly compares actual and predicted values using the following formula
accuracy(y,ŷ) =( 1/nsample)i=0nsample-11(ŷ=yi)
Where,
y = actual values
ŷ= predicted values
This simply calculates error predictions and gives the calculated error in the form of percentage values. Let’s see how we can calculate it for the above model.
from sklearn.metrics import accuracy_score
print (“Accuracy of binary classification : “, accuracy_score(y_test, y_pred)*100,”%”)
Output:
Here we can see the accuracy of our model is good enough. Let’s verify it using another evaluation method.
Confusion matrix
This method tells us how many right decisions were taken by the model. As the name suggests this is a matrix which holds the following values under the cells
Here we can see that the true positives and true negatives are the values that the model has predicted right and other values are wrongly predicted. Let’s check how many right values our model is predicting right from the test data.
import seaborn as sns
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm/np.sum(cm), annot=True,
fmt=’.1%’)
Output:
In the above, we can see that 11.7% (7.6 + 4.1) values are not accurately predicted by the model and 88.3% values are correctly predicted. Let’s take a look at how the logistic regression model is being utilised in the real world.
Application of logistic regression
There are a variety of use-cases that can be found solved using logistic regression in a variety of fields like medical, politics, engineering and marketing. For a simple example, these models can be utilised to predict the risk of disease development in a human body by observing its characteristics or for predicting the mortality of injured humans and animals.
In politics, we can use it for predicting the number of voters in an election who are going to vote for a party by observing the demographics of voters. In engineering, we find that this model is being utilised for the failure optimization or prediction of various components, processes and systems. In marketing, it is being utilised for predicting the propensity of customers regarding the purchase of any product or service using the analysis of demographics of customers.
This model can be extended to perform operations in different domains of AI where sequential data is being collected and analysed like NLP and computer vision.
Final words
In this article, we have discussed one of the basic algorithms in machine learning which is logistic regression. There are a variety of use cases where we can find this algorithm most reliable. For instance, it has been utilised for predicting the mortality of injured humans in Trauma and Injury Severity Score (TRISS). Such examples make us believe that for some simple cases we can rely on logistic regression.
Data Science Wizards (DSW) is an Artificial Intelligence and Data Science start-up that primarily offers platforms, solutions, and services for making use of data as a strategy through AI and data analytics solutions and consulting services to help enterprises in data-driven decisions.
DSW’s flagship platform UnifyAI is an end-to-end AI-enabled platform for enterprise customers to build, deploy, manage, and publish their AI models. UnifyAI helps you to build your business use case by leveraging AI capabilities and improving analytics outcomes.
Artificial intelligence is one of the most emerging fields in recent scenarios. This field aims to produce projects that can work like a human brain. Till now we can see many examples of such projects of artificial intelligence that is capable of learning, thinking and working like humans and brains of humans.
Looking at the use cases AI is solving nowadays we may think that it is a very new field but the word Artificial intelligence came in front of the world in 1956 by McCarthy at the Dartmouth conference. The effect of this can be seen in the 21st century where the world’s leading companies like Microsoft, Google, Facebook and Amazon are developing some of the states of the art projects like AdaNet, Dopamine, Alexa, Prophet, and OpenAI. These all AI projects are aiming to help humans with their daily life problems.
According to a survey by Grand View Research, the global market of artificial intelligence is having a value of USD 93.5 billion in 2021 and the projection says that it will expand by a compound annual growth rate (CAGR) of 38.1% from 2022 to 2030. The continuous research in the field is advancing the working nature of every crucial domain of the industry. In this article, we are going to look at different domains where the use of artificial intelligence is emerging very rapidly. Let’s start with the first domain!
Banking and Finance
This domain in the industry can be considered one of the early adaptors of artificial intelligence. The reason for being so is the availability of a huge amount of data and a variety of tough use-cases and problems.
Looking at the history of banking and finance we can understand that this sector plays a crucial role in human development and requires a lot of effort to avoid fraud and failures. A well-trained computer can help very much in this avoiding. Various AI programs and projects are available in the market that ensures the security of the system while helping in making a huge profit.
Various banks are also there who are providing facilities from chatbots to personal investment advisors that work based on the interests of individuals. A Variety of recommendation systems are implemented to suggest the best services and [products for the customers. Digital payment channels are designed while implementing AI agents on it. These are some of the major applications of AI in the banking and finance sector.
Healthcare
Healthcare is one of the major domains where the impact of AI is huge. We can see artificial intelligence is applied to every kind of procedure whether it is a daily or small healthcare procedure or it is a high-level healthcare procedure where we need to be accurate. A very simple example of the implementation of artificial intelligence in health care is the fit band or an iWatch which mainly works by applying sensors in the body and collecting data through it. In the end, using the artificially intelligent agent, we get pieces of information about various things such as heart rate, water required, and steps that need to be taken in a data. Sometimes we can also get notified about the abnormal effects on the body.
The above was just a use case of AI in healthcare and the implementation of AI is not ended here because in recent years we can see how artificial intelligence is applied in the generation of medication for COVID-19. Every major pharmaceutical company are applying artificial intelligence for procedures like drug discovery, robotic surgeries, virtual nursing assistant and chatbots.
Social Media
In recent scenarios, You have the power to tell people what you are doing right now using the social media channels like Facebook, Instagram, WhatsApp etc. These all channels use synthetic intelligence in the background and show us things which we may like or may want to know about. This is the power of artificial intelligence in social media.
However, we have had social media since 1971 when the first email was sent by Ray Tomlinson to himself “something like “QWERTYUIOP” written on it. From there to here social media have evolved so much and one of the main reasons behind it is artificial intelligence which helps organizations and individuals to improve their reach among a huge number of people using different algorithms.
Social media channels are not only meant to advertise yourselves but also make yourselves to be connected with the people in whom you are interested. there are a lot of applications which artificial intelligence holds in social media. Some of the basic examples are chatbots, recommendation systems, advertisement channelling etc.
Education
Artificial intelligence has brought a lot of possibilities to the education sector as well. Just, for example, AI is capable of grading educational content much faster and easier than humans. Instead of this simple example, AI is also capable of performing tasks such as task automation, personalized learning, universal accessing, smart content creation, teacher teaching, optimization of class performance, and 24/7 assistance.
Online classes are one of the major examples from the education domain where artificial intelligence has achieved a state of the art performances. Nowadays teachers are capable of managing and monitoring the academic psychological, mental and physical well-being of the students for all-round development.
E-Commerce
The E-commerce sector has become a great place for applying AI. nowadays AI has become responsible for attracting customers to boarding them safely through the E-commerce channel.
There are various use cases of AI in E-commerce such as demand and supply prediction, customer assistance, intelligent marketing, recommendation system, personalization of chatbots etc.
The biggest example of an E-commerce place is amazon which aims for the continuous development of AI so that it won’t lag in making profits out of the business. Their high-end recommendation system helps the company to attract customers and 24X7 AI-enabled assistance to manage customer requirements and complaints to provide a better user experience.
Agriculture
In the field of agriculture AI has become a game-changing player, where often AI is being used for crop monitoring, predictive analysis and robot tasking. Various systems are developed to find out the attributes of soil, seeds and atmosphere.
A simple example of AI in agriculture is drones where ai is enabled to perform tasks such as water distribution, fertilizer distribution, and detecting faults in crops.
Mechanics
By the end of the ist decade of 21 century, every major company which were manufacturing things had started using artificial intelligence in their manufacturing units and other processes. Also, automobiles are the sub-sector of mechanics which widely uses artificial intelligence not only in manufacturing but also with products. Tesla cars are one of the major examples where projects like self-driving cars, and sleep detection systems are applied with the cars.
Not only inside the cars but also on the outside we can find examples of robots which are well trained to maintain and repair the cars and manufacturing units. Apart from manufacturing systems, we find that artificial intelligence is replacing mechanical components such as pressure detectors, vernier scales, gauges etc. reliability of artificial intelligence is heavily emerging in this field.
Gaming and Sports
AI is not only powering virtual or computer gaming but also empowering physical games. Right from building reports about the players to building reports about the field and atmosphere is done by artificial intelligence. Also, there is various equipment is provided to the players that can coach and guide players well. Streaming of the games in different channels is also AI-enabled.
In virtual gaming application of AI has become so big. Nowadays we are capable to play games that are more responsive, adaptive and intelligent as non-player characters are playing the games as humans can play. AI also takes part in the development of the games. Reinforcement learning is a part of AI which mainly finds its place in virtual gaming.
Entertainment
As the uses of the internet and entertainment are increasing the application of AI is also increasing. Nowadays we can see the effect of AI in online streaming services like youtube, NetFlix, amazon prime and Hotstar.
These platforms are evolved so much so that they can recommend movies according to the user based on their interest. Such recommendation systems are being applied on this platform also just by looking at the demographic information of the users these platforms are capable of telling our interests. Where in recent scenarios we can see that new content is being created very frequently and managing them is become very easy because of applications of artificial intelligence.
Security and Surveillance
In this domain, AI came as an integration of new technology on the traditional one. Nowadays it becomes very easy for us to recognize the abnormalities in our surroundings using artificial intelligence. A huge number of tools such as face recognition tools, and object detection tools are already prepared and there is a huge number which is ready to be developed.
As AI is advancing the security and surveillance system is also advancing. One of the big examples of AI in security is the Indian armed forces and police are utilising AI-enabled drones to capture the activities like illegal border crossing, human trafficking, and illegal good supply. Also, data analysis helps a lot in predicting future crimes.
Space Researches
In space research, AI provides a very helpful hand in scaling vast realms of unravelled and undiscovered planets and universes. There are various companies such as NASA space X and ISRO which are utilising the power of AI in their space research.
For example, the recent project Mars Rovers is successfully implemented because of the utilization of AI. this p[roject helped the scientists to discover huge possibilities in the universe such as researching stars and new planets.
Every space research project are including AI to utilise it right from launching projects in space to analysing and providing results according to the requirement while avoiding human intervention.
Final words
In the article, we have discussed the domains where AI has the majority of applications. Day by day AI is developing and affecting every domain to reach its best performance. As we discussed the market potential, in the future we can see that every company is investing their time and money in the field so that they can enhance their working capabilities and profits.
At DSW, we are democratizing the power of AI through our flagship AI platform UnifyAI which can be utilised to build and solve AI-ML use-cases in any domain of the industry. UnifyAI is an end-to-end AI-enabled solution that takes your use-cases right from experimentation to production with scalability, agility and flexibility and reduces time to market for new use cases.
About DSW
Data Science Wizards (DSW) is an Artificial Intelligence and Data Science start-up that primarily offers platforms, solutions, and services for making use of data as a strategy through AI and data analytics solutions and consulting services to help enterprises in data-driven decisions.
DSW’s flagship platform UnifyAI is an end-to-end AI-enabled platform for enterprise customers to build, deploy, manage, and publish their AI models. UnifyAI helps you to build your business use case by leveraging AI capabilities and improving analytics outcomes.
In recent weeks we have got some piece of surprising news in the field of computer vision. The YOLO(You Only Look Once) series got a new member named MT-YOLOv6 which can also be called YOLOv6.
YOLO series models are well known for real-time object detection and these all models are being developed by the Ultralystics. Update by update we can see that they are enhancing the speed and accuracy of the procedure. The development of YOLOv6 took place at the Vision Intelligence Department of Meituan and one of the interesting things about the model is that it is available to everyone as an open-source. The technology team of Meituan introduced their model as YOLOv6 because they took inspiration from the original YOLO series. Let’s take a look at the comparison between the new and the older versions of YOLO.
How does MT-YOLOv6 compare to YOLOv5?
According to the research team the YOLOv6 has outperformed other YOLO models like YOLOv5 in terms of prediction accuracy and prediction speed. They have tested this model using the COCO dataset. This model is supporting various deployment platforms helping is simplifying the deployment work. Below the images is the representation of this comparison(taken from GitHub).
Here above on the right side, we can see the graph between the accuracy percentage of different models including YOLOv6 and frames processed per second while using the COCO dataset. On the left, we can see the accuracy given by the models while they are processing only one image.
In terms of development, we can consider this model as the straight-up-gradation of YOLOv5. Below are some improvements that the team has performed:
Uniformly designed backbone and neck of the system so that they can be more efficient.
Enhanced the effectiveness of decoupled head of the network using optimisation techniques.
They used an anchor-free paradigm of training while the program is getting supplemented by the SimOTA strategy of data labelling and the SloU strategy of applying bounding boxes to improve the accuracy of detection.
As discussed before, this model is open-sourced and using the link we can access the codes where pre-trained weights for nano, tiny, and small model sizes are also available.
References
Article “YOLOv6: A fast and accurate target detection framework is open source” published by Meituan technical team on June 23, 2022
About DSW
Data Science Wizards (DSW) is an Artificial Intelligence and Data Science start-up that primarily offers platforms, solutions, and services for making use of data as a strategy through AI and data analytics solutions and consulting services to help enterprises in data-driven decisions.
DSW’s flagship platform UnifyAI is an end-to-end AI-enabled platform for enterprise customers to build, deploy, manage, and publish their AI models. UnifyAI helps you to build your business use case by leveraging AI capabilities and improving analytics outcomes.
Building a machine learning model is just like making an algorithm that can perform a task like classification and regression. But when things come into production this machine learning model becomes just a block. Obviously, this block is useful in the whole architecture but alone it is just a decision-making algorithm. To make this model high performing we are required to plan a lot of things or make more blocks in the surrounding that can help the process to complete efficiently and effectively. MLOps is a set of practices that helps in streamlining the machine learning modeling procedures till the deployment in the production. Let’s know more about MLOps.
What is MLOps?
The MLOps can be considered as a set of practices/strategies/concepts/flow that we are required to use when a machine learning model is going to deploy in production. We can segregate the word MLOps into two sections: Machine Learning and DevOps.
Talking about machine learning, we can say it is a set of practices that mainly helps machines to understand and build methods that can learn. DevOps is also a combination of two words software development and IT operation. Purposely, DevOps aims to provide a scenario where the development lifecycles of various software can be shortened and continuity in delivery with higher quality can be maintained.
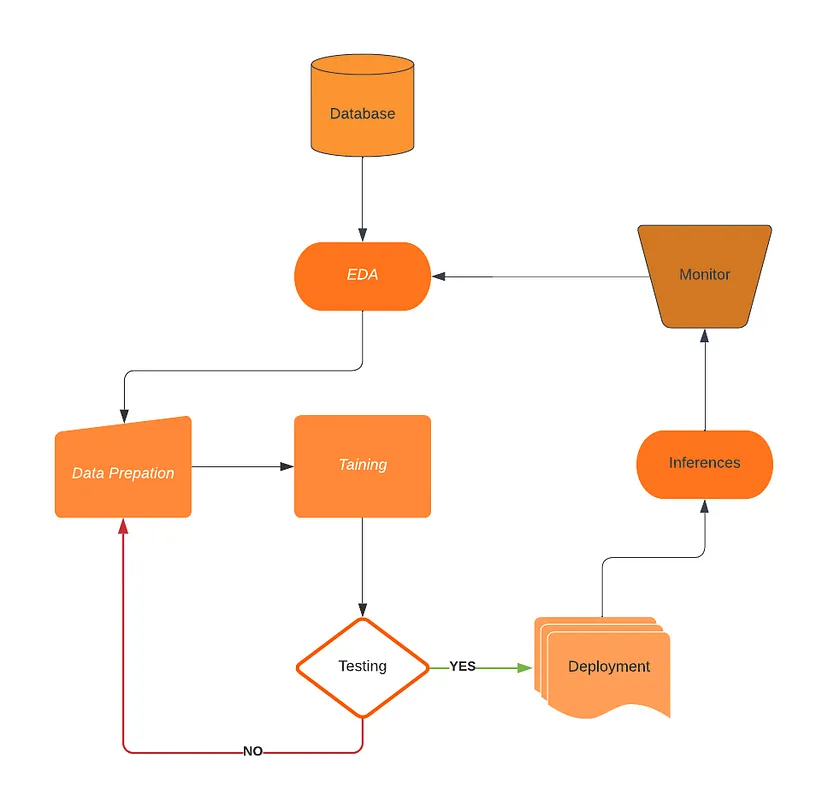
Looking at the above segregation we can say MLOps is a way to schedule processes in a way so that the development of machine learning programs can be maintained and the schedule can provide continuity in production. In more basic words we can say that the MLOps is a set of rules and regulations that makes a cycle between exploratory data analysis, data preparation, training, testing, deployment, inference, and monitoring.
Let’s take a look at the basic steps that a team of data scientists need to take care of when a model is going for the production
All the steps in the above are in the lifecycle of the model and have their different spaces. proper connectivity between them is required to make a machine learning model high performing in the production while completing the business objective.
DevOps vs MLOps
We can also say that the DevOps and MLOps are different because software from the DevOps is getting replaced by machine learning but similar because of their aim. Using the set of practices defined under MLOps we aim to increase automation in building and verifying machine learning models and improve the quality of production models while taking business and regulatory requirements into consideration.
However, the principle of DevOps came before the principle of MLOps and we can also say that MLOps is an idea extracted from the DevOps, so the fundamentals of both of these are the same. But of course, extracted parts are always difficult and here MLOps are difficult in the following points.
Development: making software work as required and making a machine learning model work as required will always have a big difference between them. Machine learning models acquire features like hyperparameters, data quality, and data quantity that are needed to set on an optimal level so that model can give a higher performance. This makes the development of the model time taking and requires a lot of effort and knowledge about the model, data, and required output.
Team composition: in software development, we can find a team full of software development while model deployment in production requires a team composed of many data scientists, ML engineers, and software engineers. Because in MLOps consists of the process of different fields like exploratory data analysis, model development, experimentation, And software development.
Testing; testing of the machine learning pipelines and model is difficult and time taking some time which varies according to the size and complexity of the data and model.
Deployment: in machine learning, different types of deployment take part like offline and online deployment. Offline deployment can seem simple but when things come in the online development which includes multistep pipelines to automatically train the model as data arrives and deploy the model again makes the deployment part of the machine learning models difficult.
Efficiency management: this also becomes difficult in the case of MLOps because there might be continuous changes in the data profile. Since data is one of the major components behind the accuracy of the machine learning models changes in data profile can harm the model’s efficiency. Also, a lot of effort is required to push in the data pipelines so that inaccurate data can be extracted from the pipelines.
There are some practices like source control, unit testing, integration testing, and continuous delivery module and packages has similar difficulties in both cases.
Benefits of MLOps
The major benefits of MLOps are as follows:
Efficiency: One of the major aims of the MLOps is to make the development cycle of the machine learning model shortened making the data teams work more efficiently by developing models faster and delivering a high-performing deployment of the models and faster production.
Scalability: MLOps can help in scaling the management and monitoring the thousands of machine learning models. Best practices can be developed and utilized to manage and monitor continuous integration, delivery, and deployment.
Risk reduction: machine learning models are best when they are in the hand of critical observation and examination and MLOps can help in maintaining this by providing transparency between inflow and response of the requests.
Principles and practices for MLOps
In the above sections, we have taken a look at the steps and cycle of the components of the modeling cycle. Using these steps and components we can set principles and practices for the MLOps. The basic principles and practices an MLOps can apply to the development are as follows:
Exploratory data analysis (EDA): this is a simple process using which a data ex[plains itself to a data analyst and data scientist. This process helps in exploring the data. Iteratively exploring the data makes us sure what portion of the data can help in fulfilling the business perspective.
Data preparation: model takes the data in different forms. Maybe there are chances that the data which is generated is not in the form supported by the model. So transforming the data according to the model is required and preparing the data for the model can require efforts from the data team.
Feature engineering: prepared data is not always the best requirement of the model. Sometimes having useless columns in the data makes the performance of the model worse and to prevent the model from performing worse feature engineering is a required process that helps in extracting only important features from the data.
Model training and tuning: after finding the best fit data for the model training of the model requires fine-tuning the model. If done so well the model can become high performing. Various library packages and modules are required to import into the pipeline at this time. One other option that can be chosen is AutoML which helps in tuning and selecting the model automatically.
Model testing and governance: track the model performance using the validation and test data to validate the model. Manage the versioning, artifacts, and transitions of the model through its life cycle. Collaborate this report with the models using some open-source platforms such as Kubeflown from Kubernetes.
Model inference and serving: after providing the testing and governance rule, set rules for managing and analyzing the model refreshes, inference request times, and other production requirements. Perform testing and QA of the model. CI/CD tools can be utilized in this phase to automate the testing pipeline.
Model deployment and monitoring: best fit model can be sent to the production after automating permissions and clustering. Enable REST API model endpoints.
Automate model retraining: set some optimal rules to provide alerts in such situations where the model start drifting due to the presence of faulty training and inference data.
Final words
In this article, we have discussed MLOps which is a set of practices similar to DevOps but applying machine learning models in place of software makes it different. Along with this, we have discussed the difference between DevOps and MLOps, the benefits of MLOps, and the Principles and practices for MLOps.
As many organization knows, training and testing models in any real-life data are not only the solution for them. Making these trained model work in real-life conditions is something the exact solution. To make such ML models work in real-life use cases, we are required to codify various components together in such a way that they can automate the workflow to reach the desired outcome. Here the concept of machine learning pipelines comes into the picture, using which organizations can not only take out desired outcomes but also keep their system healthy and flawless by monitoring production. In this article, we will delve into the space of machine learning pipelines using the following important points:
Table of contents
What is a machine learning pipeline?
What are the Components of a Machine Learning Pipeline?
Why machine learning pipelines matter?
Practices to Follow When Building a Machine Learning Pipeline
What is a Machine Learning Pipeline?
We can think of machine learning pipelines as a sequence of interconnected steps or processes involved in developing and deploying a machine learning model. When we dig down into an ML pipeline, we find it encompasses the entire workflow, from data preparation and preprocessing to model training, evaluation, and deployment. The steps and processes under such a pipeline contribute to the overall development and optimization of the machine learning model.
For most of the data science team, the ML pipelines need to be the central product as it can encapsulate all the best practices for building machine learning models to take ML models to production while ensuring the highest quality and scalability. One noticeable thing here is that by using a single machine-learning pipeline, teams can productize and monitor multiple models even when the models need to be updated frequently. So to successfully run ML applications, an end-to-end machine learning pipeline is a necessity.
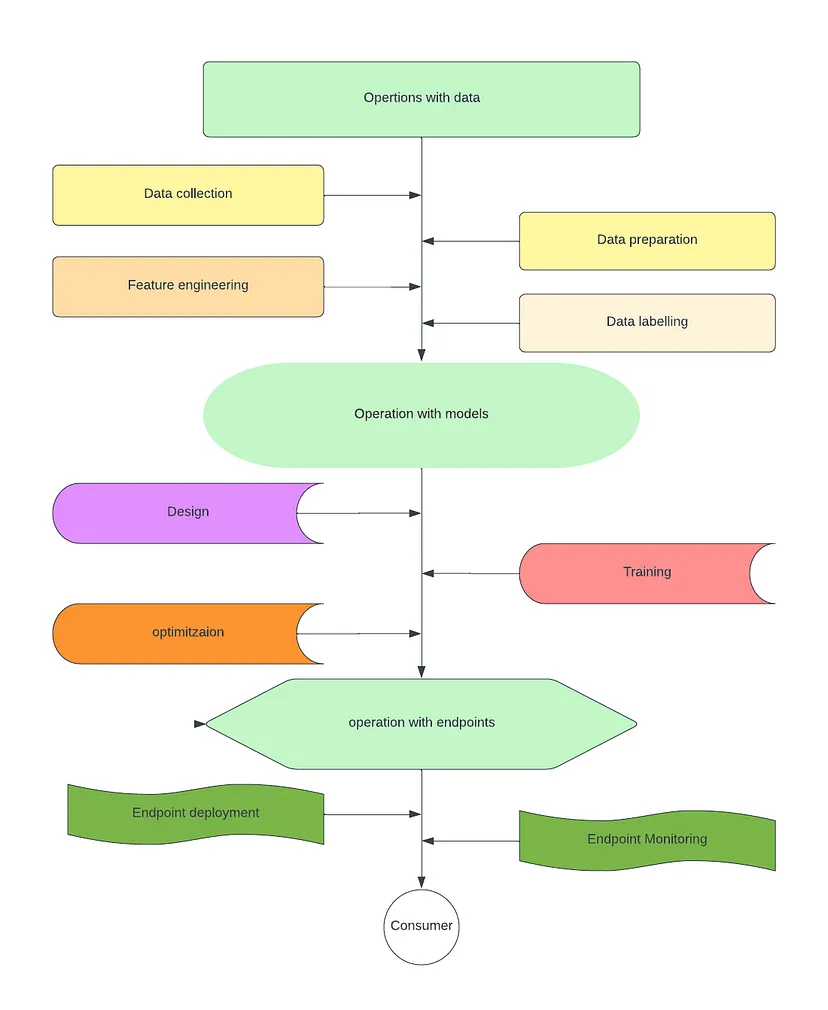
What are the Components of a Machine Learning Pipeline?
As discussed above, there are steps or processes involved in building an end-to-end machine-learning pipeline. We can consider these processes and step as the components of a machine learning pipeline. A typical machine-learning pipeline consists of the following components:
Data Preparation
Data collection: this component of the ML pipeline ensures that the data we are going to use for training models are stored in a place, or it can also be the streaming data. In the case of non-streaming data, we store the data in places like data warehouses and data lakes. But when streaming data is applied to a machine learning system, we use various techniques such as a data ingestion system, event-driven architecture, APIs and webhooks to collect the data so that data can be fed into the subsequent stages of the ML pipeline. More on Machine learning pipelines with streaming data will be discussed in the next topics. Here we will make the concept of the machine learning pipeline stronger. So let’s take a look at the next components.
Data Processing: we use this component to make data clean and transformed suitable for model usage, such as training testing and validating. This component may include processes like handling missing values, outlier detection, data normalization, and feature scaling.
Feature Engineering: This component directly impacts the performance of the model as it is the last component of the data preparation part which includes Creating new features or selecting relevant features from the available data. Here different techniques, such as one-hot encoding, feature scaling, dimensionality reduction, and creating interaction terms, can be involved.
Model Building
Model Selection: This component includes the process of choosing an appropriate machine learning algorithm or model based on the problem requirements and characteristics of the data. Here teams take time to iterate with multiple models and respective parameters.
Model Training: here, prepared data and selected machine learning models get combined and train the model by optimizing its parameters or weights to minimize a specific loss function.
Model Evaluation: this component of the pipeline help assess the performance of the trained model on unseen data using appropriate evaluation metrics such as accuracy, precision, recall, F1-score, or others depending on the problem type (classification, regression, etc.).
Hyperparameter Tuning: this component is responsible for fine-tuning the hyperparameters of the selected model to optimize its performance. This can be done through techniques like grid search, random search, or Bayesian optimization.
Model Deployment
Model deployment: this component is responsible for deploying the model into the production environment. Generally, data scientists prefer to create APIs and web services of models to deploy them, or they also deploy the models in an application or server.
Monitoring and Maintenance: this is the last component of any ML pipeline, which involves Continuously monitoring the deployed model’s performance, retraining the model periodically with new data, and making necessary updates or improvements based on feedback and changing requirements. However, we don’t consider it as the last step to take because this takes regular treatments.
After knowing the key components of machine learning pipelines, let’s take a look at why ML pipeline matters.
Why does the machine learning pipeline matter?
In the above, we got to know what exactly a machine learning pipeline is and what are the components that it involves in it. By just going through this, we can have a glimpse of its importance. Still, there are some points which we need to clarify here. So let’s take a look at the reasons which show the essentialness of the machine learning pipeline:
Efficiency and Productivity:
Streamlined Development: Machine learning pipelines provide a structured and organized approach to model development, allowing data teams to work more efficiently.
Automated Processes: Pipelines enable the automation of repetitive tasks such as data preprocessing, feature engineering, and model evaluation, which directly impact time and effort reduction.
Rapid Iteration: Pipelines enable quick experimentation by easily swapping components, testing different models or hyperparameters, and iterating on the pipeline design.
Reproducibility and Consistency:
Reusable Components: Pipelines promote the reuse of data preprocessing, feature engineering, and model training code, ensuring consistent results across different iterations or team members.
Version Control: Pipeline components can be tracked and managed using version control systems, allowing for reproducibility and easy collaboration.
Scalability and Performance:
Scalable Processing: Pipelines handle large datasets by distributing processing across multiple machines, enabling efficient scaling for training and inference.
Parallel Execution: Pipelines can execute multiple stages or components in parallel, reducing overall processing time and improving performance.
Resource Optimization: Pipelines manage resources efficiently by optimizing memory usage, minimizing computational redundancies, and leveraging distributed computing frameworks.
Deployment and Productionization:
Seamless Deployment: Pipelines facilitate the integration of trained models into production systems, enabling easy deployment as APIs, web services, or real-time applications.
Model Versioning: Pipelines support model versioning, allowing for easy tracking and managing deployed models, making updates and rollbacks straightforward.
Monitoring and Maintenance: Pipelines can include monitoring components to track model performance, detect anomalies, and trigger retraining or updates as needed.
Collaboration and Governance:
Team Collaboration: Pipelines foster collaboration by providing a common framework and structure for data scientists, engineers, and domain experts to work together.
Governance and Compliance: Pipelines can incorporate checks and validations to ensure compliance with regulations, data privacy, and ethical considerations.
Experimentation and Model Selection:
Iterative Development: Pipelines enable rapid iteration and experimentation by facilitating easy testing of different models, hyperparameters, and feature engineering techniques.
Performance Evaluation: Pipelines provide mechanisms for evaluating and comparing models based on predefined metrics, aiding in informed decision-making.
Now that we know the benefits of applying machine learning pipelines let’s learn about the practices which we should follow when seeking to apply machine learning pipelines for ML workflows.
Practices to Follow When Building a Machine Learning Pipeline
Machine learning pipelines increase the iteration cycle and give confidence to data teams; however, when we talk about building a machine learning pipeline, the starting point may vary for different teams, but it is important to follow certain practices to ensure efficient development, reproducibility, scalability, and maintainability. Here are some best practices to consider:
Define Clear Objective: when building machine learning projects, it is necessary to define the problem statement, goals, and success criteria of the whole workflow. Understanding the business need and expectations may guide us to a better development of ML pipelines.
Data Preparation: however, many teams do not consider this step as part of the ML pipeline, but before taking any data from the ML pipeline, it is necessary to Perform thorough data exploration and preprocessing. Handle missing values, outliers, and inconsistencies. Normalize, scale, or transform features as required. Split data into training, validation, and test sets for model evaluation comes in between the pipeline, and we make codes available for this in-between.
Modular Pipeline Design: we can break the pipeline into modular components such as data preprocessing, feature engineering, model training, and evaluation. While doing this, we should make these components well-defined, encapsulated, and reusable. There are frameworks and libraries, such as sci-kit-learn, TensorFlow Extended (TFX), or Apache Airflow, which can help us with modular pipeline design.
Version Control and Documentation: In the machine learning pipeline, version control tools such as helps Git to track changes, configuration files, and metadata enables reproducibility, collaboration, and easy rollback to previous versions if needed. Here documentation of pipeline components, dependencies and configuration settings explains the purpose, inputs, outputs, and usage of each component. As well as it helps in understanding and maintaining the pipeline.
Hyperparameter Tunning and Experiment Tracking: automating the process of hyperparameter tunning using techniques such as grid search, random search, or Bayesian optimization not only helps to explore different hyperparameter combinations but also saves time and effort. After that, enabling experiment tracking makes it easy to record and compare different model configurations, hyperparameters, and evaluation metrics. Tools like MLflow can help track experiments and visualize results.
Model Evaluation and Validation: The use of appropriate evaluation metrics and validation techniques helps in assessing model performance. Techniques such as Cross-validation, stratified sampling, or time-based splitting can be used depending on the data characteristics.
Performance Monitoring and Maintenance: Continuously monitoring the performance of deployed models and data ensures less chance of failures in the pipeline. So setting up a system to detect anomalies, concept drift, or degradation in model performance becomes necessary.
Security and Privacy: Ensuring data security and privacy throughout the pipeline is a compulsion. Implement measures to handle sensitive data, anonymize or encrypt data where required, and adhere to privacy regulations such as GDPR or HIPAA.
Continuous Integration and Deployment: here, we also need to implement continuous integration and deployment (CI/CD) practices to automate testing, building, and deploying the pipeline. There are tools like Jenkins, GitLab CI/CD, or Azure DevOps which can help you enable CI/CD in ML pipelines.
Here are the key practices following which we can build and deploy an efficient ML pipeline. Now let’s take a look at why we are discussing this topic.
Why are we on this topic?
We at DSW | Data Science Wizards understand that building end-to-end machine-learning pipelines is a challenging task to perform. There are various factors which we need to cater to during this development; addressing these challenges requires a combination of technical expertise, domain knowledge, collaboration, and iterative development processes. It is important to anticipate and proactively tackle these challenges throughout the pipeline development lifecycle to build robust, scalable, and efficient machine learning solutions.
To pass over such hurdles, we have built a solution platform UnifyAI, which is an advanced platform designed to address the challenges organizations face when transitioning their AI use cases from experimentation to production. Built with a strong focus on the above best practices for building efficient machine learning pipelines, UnifyAI offers a comprehensive solution to streamline and accelerate the deployment of AI models.
With UnifyAI, organizations can not only overcome the challenges associated with building ML pipelines but also experience various benefits such as End-to-End Pipeline Management, modular and flexible architecture, built-in best practices, better collaboration and governance and many more. Some key benefits of UnifyAI are as follows:
It provides all the necessary components to transform and evolve data science and AI operations from experimentation to scalable execution.
Using UnifyAI organization can eliminate repetitive data pipeline tasks and saves over 40% of your time creating and deploying new AI-enabled use cases, allowing you to focus on driving business growth.
Its unified data and model pipeline reduces overall TCO by up to 30% as organizations consider scaling their AI and ML operations.
Its well-designed monitoring system provides greater control over your data flow, models, and system performance.
In short, UnifyAI empowers organizations to unlock the full potential of their AI initiatives, enabling them to make informed decisions, drive innovation, and deliver impactful results across various industries and domains. To discover more about UnifyAI, Connect with our team. The details about us are given below.
About DSW
DSW, specializing in Artificial Intelligence and Data Science, provides platforms and solutions for leveraging data through AI and advanced analytics. With offices located in Mumbai, India, and Dublin, Ireland, the company serves a broad range of customers across the globe.
Our mission is to democratize AI and Data Science, empowering customers with informed decision-making. Through fostering the AI ecosystem with data-driven, open-source technology solutions, we aim to benefit businesses, customers, and stakeholders and make AI available for everyone.
Our flagship platform ‘UnifyAI’ aims to streamline the data engineering process, provide a unified pipeline, and integrate AI capabilities to support businesses in transitioning from experimentation to full-scale production, ultimately enhancing operational efficiency and driving growth.
In supervised machine learning, the Naive Bayes algorithm is one of the most common algorithms we can use for both binary and multiple-class classification tasks. Since it has a wide range of real-life applications, it becomes crucial to learn about the concept behind these algorithms. So in this article, we will get an introductory guide to the k-nearest neighbour using the following major points.
Table of content
What is Naive Bayes?
How does a Naive Bayes algorithm work?
Assumptions of Naive Bayes
Code example
Pros and Cons of Naive Bayes
What is Naive Bayes?
In machine learning and data science space, naive Bayes is one of the popular algorithms which we use for classification tasks. Talking about the idea behind this algorithm, we can say it is based on Baye’s theorem of probability theory, named after Reverend Thomas Bayes. According to this theorem, the probability of a hypothesis (in this case, a particular class) is proportional to the probability of the evidence (the input features) given that hypothesis.
In naive Bayes, the word Naive refers to the assumption that the input features are conditionally independent given the class. The assumption is called naive because it is generally an oversimplification of real-world scenarios where the feature can depend on each other. Let’s take an example of a text classification scenario where we often find words or text from a document as an input feature. According to this assumption, the occurrence of one word does not affect the occurrence of other words in the same document, given the class. This is often not true because, generally, the occurrence of certain words in a document can affect the likelihood of other words appearing as well. Despite this naive assumption, Naive Bayes can still perform well in many real-world applications.
Instead of dwelling more on what naive Bayes is, we can understand naive Bayes by its working. So let’s know how naive Bayes works.
How does naive Bayes work?
As discussed above, it is based on the Bayes theorem of probability subject, naive Bayes working is dependent on calculating the probability of each possible class given the input feature. Absolutely it happens when the algorithm applies Bayes’s theory. In simplification, we can understand the Bayes theory by using the following mathematical notation:
P(class | features) is the posterior probability of the class given the input features.
P(features | class) is the likelihood of the input features given the class.
P(class) is the prior probability of the class.
P(features) is the marginal probability of the evidence (i.e., the input features).
The above notation can be explained as the probability of a hypothesis of a class label given the evidence of the input features, which is directly proportional to the probability of the evidence given the hypothesis multiplied by the prior probability of the hypothesis, divided by the marginal probability of the evidence. However, here the likelihood term is calculated assuming that the input features are conditionally independent given the class, as follows:
P(features | class) = P(feature_1 | class) x P(feature_2 | class) x … x P(feature_n | class)
where feature_1, feature_2, …, feature_n are the input features, and P(feature_i | class) is the probability of feature_i given the class.
By just using the likelihood and prior probabilities, we can simplify the formula for Naive Bayes to:
P(class | features) = normalization factor x P(feature_1 | class) x P(feature_2 | class) x … x
P(feature_n | class) x P(class)
Here the normalization factor is a constant that makes the probabilities sum up to 1, and the P(feature_i | class) and P(class) can be estimated using the training data.
Basically saying, To classify a new instance, Naive Bayes calculates the probability of each possible class label given the input features. Then using the above formula, it selects the class label with the highest probability as the predicted label for the instance.
When we go deeper into the subject, we find there are three major variants of the Naive Bayes algorithm which can be used for different use cases. basic details about these variants are as follows:
Gaussian Naive Bayes: This variant is used when the input features are continuous or numerical. It assumes that the input data follows a Gaussian distribution and estimates the mean and variance of each feature for each class. This variant is widely used in classification problems that involve continuous features, such as predicting the price of a house based on its features.
Multinomial Naive Bayes: This variant is used when the input features are discrete or categorical. It assumes that the input data follows a multinomial distribution and estimates the probabilities of each feature for each class. This variant is widely used in text classification problems, such as classifying emails as spam or not spam based on their content.
Bernoulli Naive Bayes: This variant is similar to Multinomial Naive Bayes but is used when the input features are binary or Boolean. It assumes that the input data follows a Bernoulli distribution and estimates the probabilities of each feature being present or absent for each class. This variant is also widely used in text classification problems, such as classifying documents as positive or negative based on the presence or absence of certain words.
Now let’s take a look at the assumptions we might need to take care of when choosing Naive Bayes for any data modelling procedure.
Assumption of Naive Bayes
Here are the important assumptions that we should consider When applying Naive Bayes for data modelling:
First of all, the Naive Bayes assumes that the input features are conditionally independent given the class label. So Independence of Features is one of the most important assumptions to cater for naive Bayes. In a more general sense, we can say the presence or absence of one feature does not affect the probability of another feature occurring.
As the naive Bayes algorithm treats all input features as equally important in predicting the class label so the Equal Importance of Features becomes the second assumption.
When training a naive Bayes model on data, we need to consider Enough Training Data so that it can give a reliable estimation of the probabilities of the input features given the class label.
The data we use to model this algorithm should come with the Absence of Redundancy, meaning that the features should not provide redundant or overlapping information about the class label.
The training data we are using with a naive Bayes model should have a Balanced Class Distribution. Unbalanced class distribution can lead to inaccuracy of the model, or the model can become biased toward the overrepresented class.
However, in many cases, it has been seen that this model can still perform well enough if the dependence among the features is not too strong. After knowing about the basics of Naive Bayes, let’s take a look at the code implementation.
Code Example
Here, in this implementation of Naive Bayes, we are going to use Python programming language in which we get modules to generate synthetic data, split data and model functions under the libraries such as sklearn and NumPy. Let’s start the implementation by importing the libraries and the modules.
Importing libraries
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
Here, we have called the NumPy library, which we will use to make synthetic data and make calculations, and the modules for splitting and model data using the Gaussian naive Bayes model.
Generating Data
Let’s make a dataset
# Generate random data
X = np.random.rand(1000, 5)
y = np.random.randint(0, 2, size=1000)
Here, we have generated random data with 1000 samples and five features, where the target variable (y) is a binary class label.
Let’s split the data
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
Here, we have split the synthetic data into 70% training and 30% testing data.
Model training
Now, we can train the Gaussian naive Bayes model using the training data. Let’s make a model object.
# Create Naive Bayes model
model = GaussianNB()
Let’s fit the training data into the Naive Bayes model(above defined model object).
# Train model on training data
model.fit(X_train, y_train)
Output:
Here, we have trained the model object in the training data. Now we can make predictions and evaluate our model.
Model Evaluation
Let’s make a prediction out of our trained model.
# Make predictions on testing data
y_pred = model.predict(X_test)
let’s evaluate the model based on the predictions made by the model itself.
# Evaluate model performance
accuracy = np.mean(y_pred == y_test)
print(“Accuracy: “, accuracy)
Output:
# Evaluate model performance
accuracy = np.mean(y_pred == y_test)*100
print(“Accuracy: “, accuracy,’%’)
Output:
Here, we can see that our model has performed with almost 50% of accuracy. However, it is not an optimal performance, but our aim to learn about the implementation is completed.
In this list of articles, we discuss a machine learning algorithm two times where we learn the basics of algorithms the first time and in advance (second article), we see how we can use the algorithm in a more advanced manner so that we can get optimal performance from the machine learning algorithm.
So, please subscribe to us to learn the more advanced way to model data using different machine learning algorithms. Let’s take our discussion ahead and know the pros and cons of the Naive Bayes algorithm.
Pros and cons of Naive Bayes
There are several advantages and disadvantages of any machine learning algorithm. Similarly, naive Bayes has its own pros and cons. Some of them are listed below:
Pros
Naive Bayes can handle both continuous and categorical data, making it versatile for different types of datasets.
The algorithm is less prone to overfitting, which means Naive Bayes can generalize well to new data.
Naive Bayes performs well in high-dimensional datasets where the number of data features is larger than the number of data observations.
We can use Naive Bayes for both binary and multi-class classification problems.
Naive Bayes is relatively easy to implement and can be used as a baseline model for other, more complex algorithms.
Cons
The assumption of all features being independent of each other becomes a con because this is rarely true in real-world datasets.
Naive Bayes can be affected by the presence of outliers in the data.
Naive Bayes relies heavily on the quality of the input data and can perform poorly in the case of data being noisy or containing missing values.
The algorithm can have difficulties handling datasets with rare events, which can lead to underestimation of probabilities.
Naive Bayes is a probabilistic algorithm, which means that it can sometimes produce unreliable probabilities for rare events or extreme cases.
Final words
In the above article, we have discussed the naive Bayes algorithm, which is one of the popular algorithms in the machine learning space. By looking at the basic of it, we can say that it is mostly based on probability theories. This algorithm can be a good choice to work with when fewer calculations are required or the features in the dataset are independent of each other or have very low correlation. We have also discussed the assumption we need to take into account as well as the pros and cons of this algorithm.
To know more about different machine learning algorithms, one can subscribe to us. More details about us can be found below.
About DSW
DSW, specializing in Artificial Intelligence and Data Science, provides platforms and solutions for leveraging data through AI and advanced analytics. With offices located in Mumbai, India, and Dublin, Ireland, the company serves a broad range of customers across the globe.
Our mission is to democratize AI and Data Science, empowering customers with informed decision-making. Through fostering the AI ecosystem with data-driven, open-source technology solutions, we aim to benefit businesses, customers, and stakeholders and make AI available for everyone.
Our flagship platform ‘UnifyAI’ aims to streamline the data engineering process, provide a unified pipeline, and integrate AI capabilities to support businesses in transitioning from experimentation to full-scale production, ultimately enhancing operational efficiency and driving growth.
When we look into the newer practices of building machine learning projects, we find the involvement of well-designed and sustainable systems and applications that leverage ML models and other techniques connected with a data system. However, since data works as a field for these systems, we also need to ensure that data flow needs to be highly optimized, seamless and accurate from data entry points to results from outcome points. A single wrong coming in this flow can have harmful impacts on the ML project and workflow.
In the life span of such applications and systems, algorithms and models are required to keep updated constantly, redeployed and maintained regularly, which also represents the need for proper data-version management. Just for the sake of information, let’s consider an example of fraud detection systems that now a day enables ML algorithm within and recognizes data patterns. Based on that, it defines the reliability of the customer. Keeping such a system updated with the evolving domain requires constant updating. In such domain, we frequently find large data volumes over time, complex algorithms and increasing compute resources. These are signs of a scalable ML project environment.
Such an environment also represents many changes on the incoming data side. Technical requirements and industry shifts can be the reason behind the changes in the data. Making ML projects robust and flawless against these changes requires appropriate tracking and maintaining the data version. This tracking and maintaining the versions of the dataset can be called dataset version management. However, dataset version management is a crucial task for maturing ML projects, and during the process, any ML team can face the following pain:
Large data volume management without opting for data management platforms.
Ensuring the quality of datasets.
Incorporating multiple additional data sources.
Time-consuming data labelling process.
In case of sensitive data, ensure robust security and privacy policies.
In case of failure, these pain points can lead to various issues such as model degradation, data drift, security issues and many more. So as we move forward into the article, we will see in the space of data version management, associated challenges and other necessary things to adopt during ML project development.
Let’s start with knowing what data version management is,
What is Dataset Version Management?
Dataset Version Management is the process of tracking and managing different versions of a dataset. It involves creating and maintaining a history of changes made to the dataset over time, including modifications, updates, and additions. The goal of Dataset Version Management is to provide a systematic and organized way of managing datasets, allowing users to access and use different versions of the same dataset for different purposes. It is particularly important in collaborative and iterative projects, including long-term ML projects, where multiple individuals or teams are working on the same dataset and need to ensure that they are using the correct and most up-to-date version.
In the case of machine learning projects, dataset version management helps to maintain the integrity and consistency of the data throughout the project’s lifecycle. By tracking changes to the dataset, data version management enables reproducibility and transparency, ensuring that the results can be replicated and validated.
In addition, data version management helps to avoid errors and inconsistencies that can arise when different team members work with different versions of the same dataset. It also facilitates collaboration among team members by providing a centralized repository for the data, where everyone can access the latest version.
Challenges Associated with Dataset Version Management
In real-life scenarios, we have seen that the demand for data increases with the advancement of ML projects, for example, a project designed to recommend a product from an e-commerce website to its user and requiring changes frequently due to factors such as product evolution, changing customer behaviour and many more. In addition, other additional data features likely need to be considered over time so that team can ensure data relevance and accurate results.
This frequently increasing data requirement makes us think about data management solutions, and one of the most sustainable solutions is data versioning. It is not simply applying data management tools that address all the challenges experienced by ML/AI/Data teams. Some of the commonly associated challenges are as follows:
Data Aggregation: As the demand for data increases in ML projects, the number of data sources also increases, and in such scenarios, existing data pipelines need to be capable of accommodating newer data sources. There are higher possibilities that the new dataset version contains a structure different from the older one, and keeping track of what data source contains what data structure becomes a challenge.
Data Preparation: As the structure of data evolves or changes over time, we also need to evolve and change the data processing pipelines so that the data can match the structure that an ML project needs. At times, have back compatibility with previous dataset version data structures.
Data storage: As the project progresses, issues related to the scalability of both horizontal and vertical data storage become increasingly important to address, especially as the demand for storage capacity grows over time. Proper management and planning for data storage are essential to ensure that the project can handle the storage requirements throughout its lifespan.
Data Extraction: When working on machine learning projects with multiple dataset versions, it becomes crucial to keep track of which version corresponds to particular model performance. This makes it easier to retrieve the appropriate dataset version when needed and helps in reproducing the same results consistently.
The above-discussed challenges a team faces while managing the data versions in building and productizing ML projects, but the below challenges ML projects when data changes(if data pipelines are included in ML project).
Data Drift and Concept Drift
Often the ML projects that handle large data volumes evolving with time and handling complex data may face two major challenges: concept drift and data drift.
Talking about concept drift, we can say that Concept drift refers to the phenomenon in which the statistical properties of a dependent variable or the relationship between the dependent variable and its predictors change over time. In other words, it occurs when the distribution of data changes over time in a way that invalidates the assumptions made by a machine learning model. This can lead to declining performance of the model over time, as it becomes less accurate at predicting new data. It is a common problem in many real-world applications of machine learning, particularly those involving streaming data or data that changes over time. Detecting and handling concept drift is an important consideration in developing and maintaining machine learning models.
Data drift is a concept where the statistical properties of the data being used for machine learning model training and prediction change over time in unexpected ways. This can lead to performance degradation in model performance, as the model is no longer able to generalize to new data that differs from the original training set. Data drift can be caused by various factors, such as changes in the data source, data collection processes, or changes in user behaviour. Monitoring for data drift and updating machine learning models accordingly is an important part of maintaining model performance over time.
Let’s just understand this using only one example where an e-commerce website that uses machine learning to recommend multiple products to its users based on their browsing behaviour and purchasing history.
Concept drift in this scenario could occur if the website adds a new category of products, such as home appliances, to its inventory. The existing machine learning model may not have been trained on this new category of products, resulting in a change in the distribution of the input data and potentially leading to a decrease in the model’s accuracy.
Data drift, on the other hand, could occur if the behaviour of the website users changes over time. For instance, during the holiday season, users may be more inclined to buy gifts for others, providing a shift in the distribution of the input data. If the machine learning model is not updated to account for this shift, it may lead to inaccurate recommendations being made to the users.
Data annotation and preprocessing
Large-scale machine learning projects necessitate the management of significant amounts of data. However, manually annotating data may become laborious and result in discrepancies, making it difficult to maintain the quality and consistency of annotations.
Data preprocessing is the process of transforming completely raw data into the most suitable format for analysis and modelling. As long-term projects advance, the preprocessing methods may evolve to better tackle the problem at hand and enhance model performance. This could result in the developing of numerous dataset versions, each with its own set of preprocessing techniques. Other challenges related to data annotation and processing are as follows:
Complex data growth often leads to time-consuming and inefficient processing tasks, which also affect training time and decrease efficiency.
The lack of standardization in processing the data leads to unstable quality and accuracy of the data.
Maintaining the quality and consistency of data is also challenging, often more challenging when the raw data changes.
Data security and privacy
Maintaining data security and privacy in ML projects is essential, and applying data versioning management with this becomes a challenging task to complete. Where data security ensures data protection from unauthorized access, destruction and modification during data storage, processing and transmission. On the other hand, data privacy ensures the protection of personal information and gives the right to handle and control information sharing of every individual.
In machine learning projects, managing and versioning datasets is essential, but it also poses significant challenges in terms of data security and privacy. Protecting sensitive data within machine learning pipelines is crucial to prevent severe consequences such as legal liability, loss of trust, and reputational damage caused by security breaches or unauthorized data access. Therefore, implementing robust data security measures is essential to ensure the privacy and confidentiality of sensitive data throughout the machine learning project’s lifecycle.
Practices to Follow for Data Version Management
As discussed above, data version management is crucial for building seamless machine learning projects, and also it is a challenging task to perform as it includes many considerations to take care of. However, we are required to cope with these challenges and follow the best practices to make data version management easy, accurate and flawless.
In this section, we will explore the practices we need to address the above-mentioned challenges. These practices are essential for data teams to follow in case of teams are looking to build and run ML projects for a long time. Let’s take a look at them one by one.
Data Storage
When it comes to data storage in long-term machine learning projects, there are several best practices that can help ensure smooth and efficient storage and retrieval of data over time. Some of these practices include:
Choosing the right data storage technology that can scale horizontally and vertically and accommodate different types of data.
Implementing data compression and indexing to reduce the size of the data being stored and speed up search and retrieval times
Setting up a backup and recovery system to protect against data loss and minimize downtime in the event of a disaster.
Regularly monitoring and optimizing data storage performance to identify and address issues before they become more significant problems.
Data Retrieval
Nowadays, machine learning systems are designed to perform enough data retrieval in different procedures such as training, analysis and validation time. This makes data retrieval a crucial process for accurate model training, data-driven insights, and decision-making. So when it comes to data retrieval in long-term machine learning (ML) projects, it is important to follow the following practices:
Maintain a record of dataset versions.
Add metadata to datasets that can help in understanding the dataset’s content and context.
Have a clear process for retrieving data and ensure it is documented
Use appropriate tools to store and retrieve data, such as data lakes or cloud storage services, that offer scalability, availability, and security.
Data Version Control
When considering data version control in long-term machine learning projects, here are some best practices to follow:
Use a version control system (VCS) to manage changes to the code and data over time. This allows you to keep yourselves updated with the changes and revert to previous versions if necessary.
Use a naming convention to label and identify different versions of the data. This could include a combination of the date, version, and a brief description of the changes.
Keep a record of the data preprocessing techniques used for each dataset version. This includes the data cleaning, feature engineering, and normalization techniques used.
Store the data in a scalable and secure data storage system. This ensures that the data can be accessed and managed easily over time and is protected from security threats and breaches.
Establish clear ownership and access control policies for the data to ensure that only authorized individuals have access to the data and that everyone knows who is responsible for managing the data.
Tools that can help in following these practices include Git for version control, DVC for data version control, cloud-based storage solutions like Amazon S3 or Google Cloud Storage for scalable and secure data storage, and access control tools like AWS IAM or Google Cloud IAM for managing access to the data.
Team Collaboration
Team collaboration plays a crucial role in ensuring the appropriate data version management and overall ML project success. Generally, building an ML project requires a varying number of team members and various disciplines. A clear role definition under a team enables efficient collaboration and promotes accountability. Here are some team collaboration and role definition practices which can help data version management to become efficient:
Defining roles to ensure high-performing data acquisition, annotation, and processing. Generally, these works are done by a data manager.
A data analyst needs to be assigned to the project to perform data visualization, analysis, feature extraction, and exploration.
Data versioning, documentation, and security factors need to be explained properly to every member of the team.
There are tools such as DVC and platforms that come with capabilities such as team member tagging, updating audits and commenting. Using these capabilities, we can improve the synergy between various team members and teams.
Efficient communication is crucial for team collaboration. It’s essential to have standard communication protocols and change procedures in place and to document and communicate them to team members. This includes establishing a code review process, identifying solution and platform owners, and setting meeting frequencies to ensure efficient collaboration. By doing so, issues can be identified and resolved appropriately, leading to better project management and improved results.
Dataset Documentation
For any development project, documentation is a key aspect and becomes crucial in many places, and here also, it is necessary to adopt tools within the team which can help in data documentation. It easily enables team members to record notes, context and knowledge to ensure reproducibility. This also helps in knowledge transfer between team members.
The following important details about any dataset can be documented appropriately:
Source
Business relevance
Author
Creation and modification details with dates
Format of the data values.
There are other benefits of dataset documentation, such as it helps comply with data governance because users the hood we get the capabilities to document data policies, lineage, and privacy information.
Data understanding and team collaboration are also other factors that dataset documentation caters to appropriately. However, these tools are subjected to financial investment, but they can evolve with the project phases if applied correctly.
Conclusion
In this article, we have explored the subject of dataset version management, which becomes a crucial step to take when applying ML projects with different data. Although there are challenges which data teams need to address in the process of data version management, some simple practices can be a huge help in making this complex process easy and efficient.
Data Science Wizards provides organizations with our platform UnifyAI to implement AI and ML in their operations. We understand that data version management is an essential step for any end-to-end ML/AI project. Hence, we have created a comprehensive guide that organizations can use to enable data version management within their systems. With this guide, organizations can easily track, manage and handle data versions, ensuring accurate reproducibility, collaboration, data security, and Better decision-making.
About DSW
DSW, specializing in Artificial Intelligence and Data Science, provides platforms and solutions for leveraging data through AI and advanced analytics. With offices located in Mumbai, India, and Dublin, Ireland, the company serves a broad range of customers across the globe.
Our mission is to democratize AI and Data Science, empowering customers with informed decision-making. Through fostering the AI ecosystem with data-driven, open-source technology solutions, we aim to benefit businesses, customers, and stakeholders and make AI available for everyone.
Our flagship platform ‘UnifyAI’ aims to streamline the data engineering process, provide a unified pipeline, and integrate AI capabilities to support businesses in transitioning from experimentation to full-scale production, ultimately enhancing operational efficiency and driving growth.